Замечали ли вы, что отчеты различных инструментов дают разные показатели производительности? Не должны ли они быть одинаковыми, если отчеты основаны на использовании одной и той же базовой технологии для генерации показателей? Мы рассмотрим, как различные инструменты формируют отчеты по метрикам производительности, таким как core web vitals.
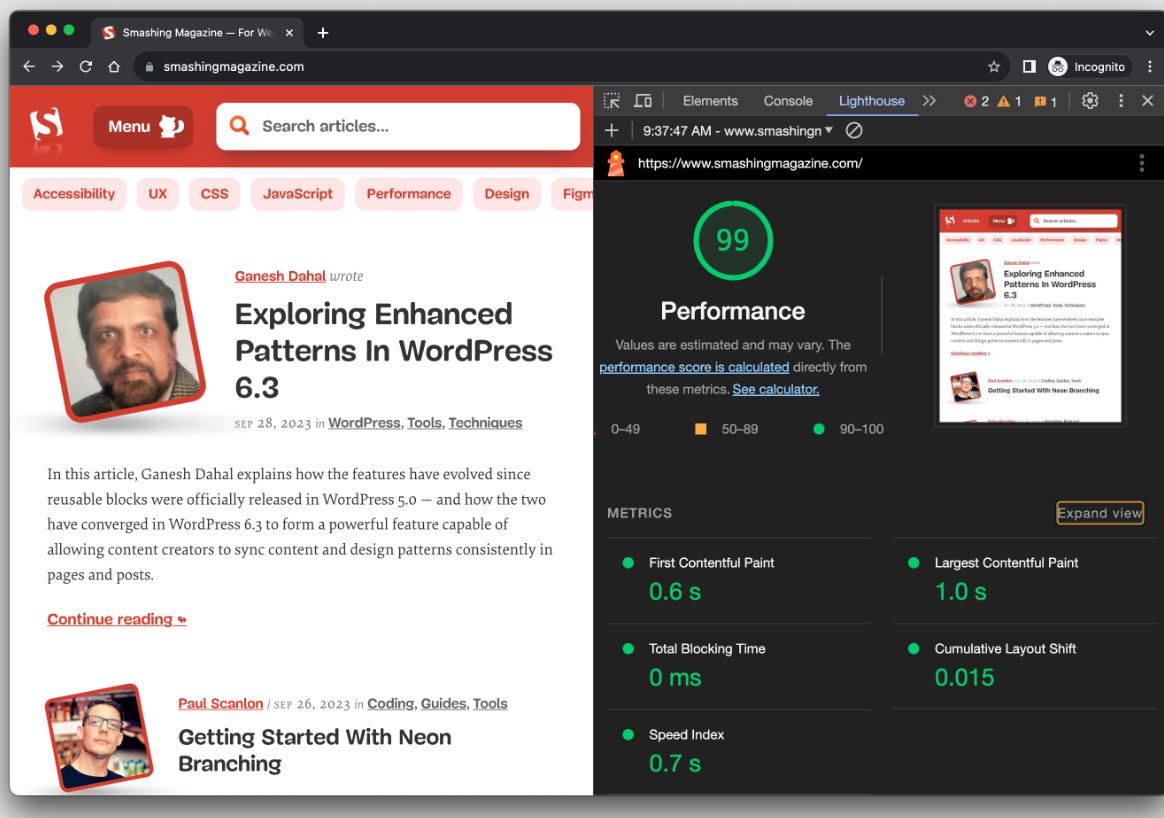
Проверка производительности вашего сайта — не слишком сложная задача. Возможно, вы делаете ее регулярно с помощью бесплатного инструмента Lighthouse в Chrome DevTools, получая привлекательный отчет.
Lighthouse — всего лишь еще один инструмент для аудита производительности среди множества других. Удобство его наличия в Chrome DevTools делает его популярным выбором для многих разработчиков.
Знаете ли вы, как именно Lighthouse рассчитывает метрики производительности, такие как First Contentful Paint (FCP), Total Blocking Time (TBT) и Cumulative Layout Shift (CLS)?) В сводке отчета есть удобный калькулятор, который позволяет корректировать значения производительности, чтобы увидеть, как они влияют на общую оценку. Однако там нет информации о данных, которые Lighthouse использует для оценки метрик. Следующее разъяснение дает больше подробностей, начиная от того, как весовые коэффициенты определяют оценку, и заканчивая причинами колебания оценок между запусками тестов.
Зачем нам вообще нужен Lighthouse, если Google также предлагает аналогичные отчеты в PageSpeed Insights (PSI)? Суть в том, что эти два инструмента сильно различались до того, как PSI был обновлен в 2018 году с целью перехода к отчетам Lighthouse.
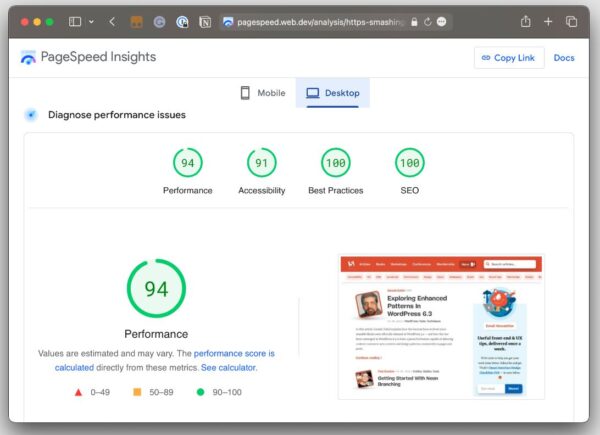
Вы, возможно, заметили, что оценка производительности в Lighthouse отличается от аналогичного скриншота в PSI. Почему в случае использования одного инструмента оценка почти идеальная, а в случае использования другого появляются дополнительные причины для ее снижения? Не должны ли оценки быть одинаковыми, ведь оба отчета опираются на одинаковые инструменты?
Об этом и рассказывается в этой статье. Разные инструменты, будь то Lighthouse, PageSpeed Insights или коммерческие сервисы, делают разные предположения на основе разных данных. Вот что является причиной разброса результатов. Но есть и более конкретные причины для расхождения.
Давайте разберемся в них, ответив на ряд часто возникающих вопросов в ходе аудита производительности.
- Что означает заявление PageSpeed Insights о том, что он использует «данные реального пользовательского опыта»?
- Тип 1: Отчет о пользовательском опыте в Chrome (CRUX)
- Тип 2. Полный мониторинг реальных пользователей (RUM).
- Lighthouse использует RUM-данные?
- Тип 1. Наблюдаемые данные.
- Тип 2. Симулированные данные.
- Симулированные и наблюдаемые данные в Lighthouse
- Ограничения лабораторных данных
- Почему мой показатель LCP в Lighthouse хуже, чем реальные данные пользователей?
- Почему мой показатель CLS, полученный с помощью инструмента Lighthouse, лучше, чем реальные данные пользователей?
- Почему метрика Interaction To Next Paint отсутствует в моем отчете Lighthouse?
- Почему мой показатель Time To First Byte хуже, чем у реальных пользователей?
- Почему разные инструменты дают разные значения Core Web Vitals? Какие значения являются правильными?
- Заключение
Что означает заявление PageSpeed Insights о том, что он использует «данные реального пользовательского опыта»?
Это отличный вопрос, потому что он дает дополнительный контекст для объяснения возможных различий в результатах разных инструментов аудита производительности. Фактически, когда мы говорим о «данных реальных пользователей», мы на самом деле имеем в виду два разных типа данных. И, обсуждая эти два типа данных, мы фактически говорим о том, что называется мониторингом реальных пользователей (real-user monitoring), или RUM сокращенно.
Тип 1: Отчет о пользовательском опыте в Chrome (CRUX)
«Данные о реальном пользовательском опыте» в PSI означают, что при оценке производительности в ваших тестах все показатели web core vitals сравниваются с аналогами, полученными от реальных пользователей. Эти данные о реальном опыте берутся из отчёта Chrome User Experience (CrUX), который содержит анонимную информацию, собранную у пользователей Chrome — по крайней мере у тех, кто дал свое согласие на обработку данных.
Данные CrUX важны, потому что они используются для измерения показателей web core vitals, которые, в свою очередь, являются фактором ранжирования в результатах поиска Google. Для Google важен 75-й процентиль пользователей в данных CrUX при предоставлении метрик core web vitals. Таким образом, данные отражают большинство пользователей, минимизируя возможность выбросов.
Ознакомиться с перцентилями, выбросами и другими терминами можно в следующем видео:
Также вы можете прочитать следующую статью, если не хочется смотреть ролик.
p.s. Процентиль, перцентиль — это все одно и то же.
Но при этом есть некоторые ограничения. Например, данные обновляются довольно медленно — каждые 28 дней — это не то же самое, что мониторинг в реальном времени. В то же время, если вы планируете использовать данные самостоятельно, вы можете прибегнуть к CrUX History API или BigQuery для получения исторических результатов, которые можно будет сравнивать. CrUX является основой для PSI и Google Search Console, но также доступен и в других инструментах.
Тип 2. Полный мониторинг реальных пользователей (RUM).
Полный мониторинг реальных пользователей (RUM) – еще один тип данных, который предоставляет дополнительный контекст: к примеру, конкретные сетевые запросы, сделанные страницей. Эти данные отличаются от CrUX, поскольку они собираются непосредственно владельцем веб-сайта путем установки аналитического кода на свой сайт.
В отличие от данных CrUX, полные данные RUM собираются от пользователей разных браузеров, не только Chrome, и идет этот процесс непрерывно. Это означает, что нет необходимости ждать 28 дней для получения свежего набора данных и оценки влияния любых изменений на сайте.
Вы можете увидеть, как разные типы мониторинга данных реальных пользователей (RUM) могут привести к различным результатам в тестах производительности.
Оба типа полезны, но, как вы можете обнаружить, результаты на основе CrUX подходят для получения общего представления о производительности; они не являются точным отражением пользовательского поведения на вашем сайте из-за 28-дневного периода ожидания. В этом контексте выигрывает RUM со своими мгновенными результатами и большей глубиной информации.
Lighthouse использует RUM-данные?
Нет! Lighthouse использует синтетические данные (то, что мы обычно называем лабораторными данными). Как и в случае с RUM, мы опишем концепцию лабораторных данных, разделив их на два разных типа.
Тип 1. Наблюдаемые данные.
Наблюдаемые данные — это производительность, как ее видит браузер. Наблюдаемые данные больше похожи на определение условий тестирования. Например, мы можем добавить ограничение по скорости коннекта в тестовую среду, чтобы создать искусственное условие, при котором страница в тесте будет открываться с более медленным Интернет-соединением. Вы можете представить это себе как автомобильный заезд в виртуальной реальности, где условия прописаны заранее, а не гонку на реальной трассе, где условия могут меняться.
Тип 2. Симулированные данные.
Хотя мы и назвали первый тип «наблюдаемыми данными», этот термин не является устоявшимся в отрасли. Это скорее необходимая метка, которая помогает отличить их от симулированных данных, используемых в Lighthouse (и во множестве других инструментов, включая PSI) с целью регулировки тестовой среды и получаемых результатов.
Причина для такого разделения заключается в том, что существуют разные способы ограничения скорости сети для тестирования. Симулированное ограничение начинается со сбора данных на быстром Интернет-соединении, после чего происходит оценка, с какой скоростью страница загрузилась бы на другом соединении. Результатом является более быстрое тестирование, нежели в том случае, когда ограничение пропускной способности задается еще до сбора информации. С симулированными данными Lighthouse может получать результаты и вычислять оценки быстрее, чем при сборе данных и обработке их на искусственно замедленном соединении.
Симулированные и наблюдаемые данные в Lighthouse
Симулированные данные — это данные, которые по умолчанию используются в Lighthouse для отчетов о производительности. Именно такие данные использует PageSpeed Insights, поскольку он работает на основе Lighthouse, хотя PageSpeed Insights также опирается на данные от реальных пользователей из отчета CrUX.
При этом в Lighthouse также можно собрать и наблюдаемые данные. Эти данные более надежны, поскольку они не зависят от неполной симуляции Chrome и сетевого стека. Точность наблюдаемых данных обусловлена настройками тестовой среды. Если задано ограничение пропускной способности на уровне операционной системы, то метрики соответствуют тому, что испытал бы реальный пользователь при таких сетевых условиях. Ограничения DevTools проще в настройке, но они лишь примерно отражают работу серверных соединений в сети.
Ограничения лабораторных данных
Лабораторные данные имеют фундаментальное ограничение, заключающееся в том, что они рассматривают только одно ранее определенное взаимодействие в заданной среде. Эта среда часто не равна среднему реальному пользователю на веб-сайте, у которого может быть более быстрое сетевое подключение или медленный CPU. Однако непрерывный мониторинг реальных пользователей действительно позволяет узнать, как пользователи взаимодействуют с вашим веб-сайтом и достаточно ли он быстрый.
Зачем вообще использовать лабораторные данные, если они имеют свои ограничения?
Главное преимущество лабораторных данных состоит в том, что они дают более подробную информацию, чем мониторинг реальных пользователей.
«Данные от Google CrUX сообщают только значения метрик без отладочной информации, позволяющей улучшить показатели. В отличие от них, лабораторные отчеты содержат более детальный анализ и рекомендации о том, как улучшить скорость загрузки вашей страницы.»
Почему мой показатель LCP в Lighthouse хуже, чем реальные данные пользователей?
Теперь, когда мы знакомы с разными типами данных, используемыми инструментами для проверки производительности, нам будет немного проще разобраться в показателях. Теперь мы знаем, что Google рассматривает 75-й процентиль реальных пользователей в отчетах web core vitals, включая LCP.
«Используя 75-й процентиль, мы знаем, что большинство посещений сайта (3 из 4) осуществлялись с целевым уровнем производительности или выше. Кроме того, значение 75-го процентиля менее подвержено выбросам. Вернемся к нашему примеру: для сайта со 100 посещениями 25 из этих посещений должны содержать большие выборки выбросов, чтобы значение на 75-м процентиле было затронуто ими. Хотя вероятно, что 25 из 100 выборок могут быть выбросами, это гораздо менее вероятно, чем в случае с 95-м процентилем.»
С другой стороны, симулированные данные Lighthouse не отражают реальных пользователей и не учитывают выбросы так, как это делает CrUX. Если бы мы установили сильное ограничение на процессор или сеть в тестовой среде в Lighthouse, мы фактически охватили бы выбросы, которые CrUX игнорирует. Поскольку Lighthouse по умолчанию применяет сильное ограничение пропускной способности, результатом является показатель LCP хуже, чем в PSI, просто потому что данные Lighthouse эффективно учитывают медленные выбросы.
Почему мой показатель CLS, полученный с помощью инструмента Lighthouse, лучше, чем реальные данные пользователей?
Показатель Cumulative Layout Shift (CLS) измеряет «визуальную стабильность» макета страницы. Если вы когда-либо посещали страницу и прокручивали ее вниз еще до полной загрузки, после чего замечали, что ваше положение на странице вдруг перескочило после завершения загрузки, то вы точно знаете, что такое CLS и как он ощущается.
Здесь есть нюанс, связанный с взаимодействием со страницей. Мы знаем, что реальные пользователи способны взаимодействовать со страницей даже до ее полной загрузки. Это важно при измерении CLS, так как сдвиги макета часто происходят внизу страницы после ее прокрутки пользователем. Данные CrUX идеально подходят здесь, поскольку они основаны на действиях реальных пользователей, которые могут поступать так и страдать от последствий CLS.
С другой стороны, симулированные данные Lighthouse не ведут себя так. Они терпеливо ожидают полной загрузки страницы и никак не взаимодействуют с ее частями. Они не прокручивают, не кликают, не тапают, не наводят курсор и не взаимодействуют со страницей никаким образом.
Поэтому в отчете PSI вы скорее получите более низкий показатель CLS, чем в Lighthouse. Не то чтобы PSI менее благосклонно относится к вам, просто реальные пользователи в его отчете лучше взаимодействуют со страницей и более вероятно испытают CLS, чем симулированные лабораторные данные.
Почему метрика Interaction To Next Paint отсутствует в моем отчете Lighthouse?
Это ещё один случай, когда полезно разбираться в различных типах данных, используемых в разных инструментах, и как эти данные взаимодействуют — или не взаимодействуют — со страницей. Потому что метрика Interaction to Next Paint (INP) полностью основана на взаимодействии. Это ясно уже из названия!
То, что симулированные лабораторные данные Lighthouse не взаимодействуют со страницей, делает невозможным получение отчёта по метрике INP. INP представляет собой измерение времени ожидания всех взаимодействий на определенной странице, где самая высокая задержка — или близкая к ней — влияет на итоговый балл. Например, если пользователь нажимает на аккордеон и загрузка его содержимого занимает больше времени, чем любое другое взаимодействие на странице, именно это значение будет использоваться для расчета INP.
Так что, когда INP станет официальной метрикой core web vitals с марта 2024 года, и вы заметите, что она отсутствует в вашем отчёте Lighthouse, вы точно будете знать, почему она не отображается.
Примечание: Вы можете использовать скрипты пользовательских действий в Lighthouse. Но это, вероятно, выходит за рамки данной статьи.
Почему мой показатель Time To First Byte хуже, чем у реальных пользователей?
Время до первого байта (TTFB) — это то, о чем сразу же думают многие из нас, когда речь заходит о скорости загрузки страницы. Мы говорим о времени между установлением соединения с сервером и получением первого байта данных для отображения страницы.
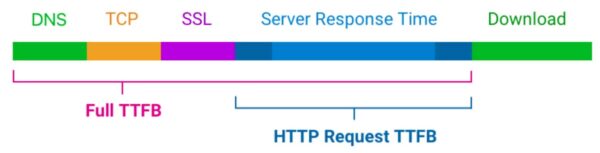
TTFB (Time To First Byte) определяет, насколько быстро или медленно веб-сервер реагирует на запросы. Это время особенно важно в контексте метрик core web vitals, даже если оно само по себе не является одной из них. Веб-серверу необходимо установить соединение, чтобы получить первый байт данных и отобразить всё остальное, что и оценивается с помощью core web vitals. TTFB в основном указывает на то, как быстро пользователи могут совершать навигацию, и без него core web vitals не имеют смысла.
Вы уже можете представить, куда это ведет. Когда мы начинаем говорить о соединении с сервером, возникают различия в том, как данные RUM (реальных пользователей) и лабораторные данные определяют TTFB. В результате мы получаем разные показатели эффективности в зависимости от инструментов и среды, в которой они используются. Поэтому TTFB является скорее «грубой ориентировкой», как объясняют Джереми Вагнер и Барри Поллард:
Веб-сайты различаются в способе доставки контента. Быстрый первый отклик (TTFB) крайне важен для оперативной передачи разметки клиенту. Веб-сайт может быстро передавать начальную разметку, но для заполнения этой разметки содержательным контентом может потребоваться JavaScript […]. Минимально возможный показатель TTFB важен для того, чтобы клиентская обработка разметки могла пройти быстрее. […] Именно поэтому пороговые величины TTFB являются «грубой ориентировкой» и их нужно сопоставлять с тем, как ваш сайт доставляет основной контент.
Таким образом, если ваш показатель TTFB выше при использовании инструмента, который основывается на данных RUM, чем показатель, полученный из лабораторных данных Lighthouse, вероятно, это связано с тем, что при тестировании конкретной страницы используются кэшированные данные. Или, возможно, реальный пользователь заходит через укороченный URL, который перенаправляет его до подключения к серверу. Также возможно, что реальный пользователь подключается из места, находящегося довольно далеко от вашего веб-сервера, что занимает немного больше времени, особенно если вы не используете CDN. Это действительно зависит от пользователя и способа предоставления данных.
Почему разные инструменты дают разные значения Core Web Vitals? Какие значения являются правильными?
В этой статье уже была описана некоторая сложность сбора данных core web vitals. Различные инструменты и источники данных часто сообщают разные значения метрик. Каким из них можно доверять?
При работе с лабораторными данными я рекомендую предпочесть наблюдаемые данные перед симулированными. Однако, вы все равно будете видеть различия даже между инструментами, предоставляющими высококачественные данные. Это связано с тем, что никакие два теста не будут одинаковыми, они проходят в разных местах, на разных скоростях ЦП и в разных версиях Chrome. Нет единого правильного значения. Вместо этого вы можете использовать лабораторные данные для выявления оптимизаций и просмотра изменений вашего веб-сайта со временем при тестировании в одной и той же среде.
В конечном итоге вам нужно оценить реальное впечатление пользователей от вашего сайта. С точки зрения SEO, золотым стандартом являются данные Google CrUX за последние 28 дней. Однако они могут быть неточными, если вы вносили улучшения производительности в течение последних пары недель. Google также не приводит данные CrUX для отдельных страниц с большим трафиком, потому что посетители могут быть неавторизованными в профиле Google.
Установка специального решения RUM на вашем веб-сайте может решить эту проблему, но показатели не будут точно соответствовать CrUX. Все потому, что включаются посетители, использующие браузеры, отличные от Chrome, а также пользователи с отключенной аналитикой в Chrome.
Наконец, хотя Google фокусируется на 75% выборок, это не означает, что 75-й процентиль является правильным числом для оценки производительности. Даже при хороших показателях core web vitals, 25% посетителей могут все равно иметь медленный опыт взаимодействия с вашим веб-сайтом.
Заключение
Мы рассмотрели то, как различные инструменты для проверки производительности вычисляют метрики, такие как core web vitals. Разные инструменты опираются на разные типы данных, которые способны давать несхожие результаты при оценке тех или иных метрик производительности.
Так что, если вы обнаружите, что значение CLS в Lighthouse на порядок лучше, чем в PSI, выберите отчет Lighthouse, потому что он будет выглядеть симпатичнее в глазах вашего руководства. Шутка! Это различие является большой подсказкой, что данные между этими двумя инструментами неоднородны, и вы можете использовать эту информацию для диагностики и устранения проблем с производительностью.
Источник: smashingmagazine.com